I Blocked Bots
—
- blog
- 5
- 2
- finished
Yesterday I started blocking crawlers via robots.txt. I was forced to because it started getting out of hand. I’ll observe traffic for a few days and will block them on level of HTTP server or fail2ban/iptables if it turns out that they don’t respect robots.txt, contrary to the claims of the biggest offenders.
This is mostly low-profile site. Me, my family and maybe some of my friends are doing at most 500-600 requests a day, a little more if I’m tinkering with server.
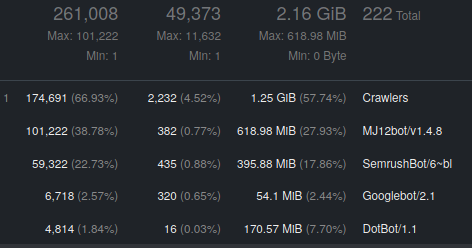
There are 2 main contributors to the increased traffic: MJ12 and SemRush. Above is part of goaccess’ report from last 14 days. It is clear that these 2 bots alone do over 11000 requests a day, which is insane for a site known by maybe 10 people on Earth. It’s nowhere near the capacity of the server, but it translates to 2 GB of transferred data every month. Wasted 2 GB, because those bots give me nothing. I don’t even think I’m serving that many pages in total, including some dynamically generated.
Cherry on top: I’m not the only one who hates these bots. Wikipedia hates MJ12 especially as well. And others too.
Update: 2020-03-03
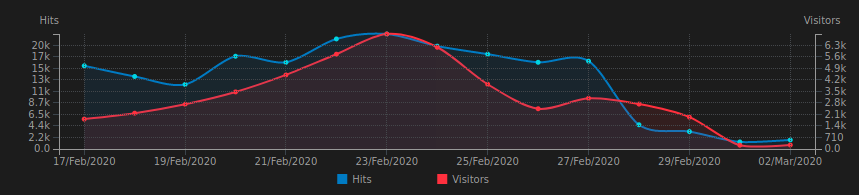
After few days it seems that robots.txt trick worked as things calmed down. I had to add robots.txt to every subdomain though, some disallowing all bots and some merely delaying requests (via non-standard Crawl-Delay directive). Still, there are more requests than I’d expect, but I have to evaluate those before saying anything else.
Update: 2023-02-01
robots.txt method turned out to be error-prone. At some point I moved my robots.txt file to a different directory and forgot to point nginx to it. As you can imagine, all bots suddenly saw no robots.txt and resumed crawling my site.
But even after fixing it, many refused to obey, even if they documented otherwise. One which I hate the most, as it was number 1 in my logs, “attacking” my site every 1-2 seconds, is Amazonbot.
I released fail2ban onto them. Currently there are different 69 bots blocked which crawled my site in the last 168 hours. Here are the configuration files:
# An entry in /etc/fail2ban/jail.local
[nginx-badbots]
enabled = true
port = http,https
filter = nginx-badbots
logpath = %(nginx_access_log)s
maxretry = 1
findtime = 604800
bantime = 604800
# /etc/fail2ban/filter.d/nginx-badbots.conf
[Definition]
badbots = Amazonbot|360Spider|404checker|404enemy|80legs|Abonti|Aboundex|Acunetix|ADmantX|AfD-Verbotsverfahren|AhrefsBot|AIBOT|AiHitBot|Aipbot|Alexibot|Alligator|AllSubmitter|AlphaBot|Anarchie|Apexoo|ASPSeek|Asterias|Attach|autoemailspider|BackDoorBot|Backlink-Ceck|backlink-check|BacklinkCrawler|BackStreet|BackWeb|Badass|Bandit|Barkrowler|BatchFTP|Battleztar Bazinga|BBBike|BDCbot|BDFetch|BetaBot|Bigfoot|Bitacle|Blackboard|Black Hole|BlackWidow|BLEXBot|Blow|BlowFish|Boardreader|Bolt|BotALot|Brandprotect|Brandwatch|Bubing|Buddy|BuiltBotTough|BuiltWith|Bullseye|BunnySlippers|BuzzSumo|Calculon|CATExplorador|CazoodleBot|CCBot|Cegbfeieh|CheeseBot|CherryPicker|ChinaClaw|Chlooe|Claritybot|Cliqzbot|Cloud mapping|coccocbot-web|Cogentbot|cognitiveseo|Collector|com\.plumanalytics|Copier|CopyRightCheck|Copyscape|Cosmos|Craftbot|crawler4j|crawler\.feedback|CrazyWebCrawler|Crescent|CSHttp|Curious|Custo|DatabaseDriverMysqli|DataCha0s|DBLBot|demandbase-bot|Demon|Deusu|Devil|Digincore|DigitalPebble|DIIbot|Dirbuster|Disco|Discobot|Discoverybot|DittoSpyder|DnyzBot|DomainAppender|DomainCrawler|DomainSigmaCrawler|DomainStatsBot|Dotbot|Download Wonder|Dragonfly|Drip|DTS Agent|EasyDL|Ebingbong|eCatch|ECCP/1\.0|Ecxi|EirGrabber|EMail Siphon|EMail Wolf|EroCrawler|evc-batch|Evil|Exabot|Express WebPictures|ExtLinksBot|Extractor|ExtractorPro|Extreme Picture Finder|EyeNetIE|Ezooms|FDM|FemtosearchBot|FHscan|Fimap|Firefox/7\.0|FlashGet|Flunky|Foobot|Freeuploader|FrontPage|Fyrebot|GalaxyBot|Genieo|GermCrawler|Getintent|GetRight|GetWeb|Gigablast|Gigabot|G-i-g-a-b-o-t|Go-Ahead-Got-It|Gotit|GoZilla|Go!Zilla|Grabber|GrabNet|Grafula|GrapeFX|GrapeshotCrawler|GridBot|GT\:\:WWW|Haansoft|HaosouSpider|Harvest|Havij|HEADMasterSEO|Heritrix|Hloader|HMView|HTMLparser|HTTP\:\:Lite|HTTrack|Humanlinks|HybridBot|Iblog|IDBot|Id-search|IlseBot|Image Fetch|Image Sucker|IndeedBot|Indy Library|InfoNaviRobot|InfoTekies|instabid|Intelliseek|InterGET|Internet Ninja|InternetSeer|internetVista monitor|ips-agent|Iria|IRLbot|Iskanie|IstellaBot|JamesBOT|Jbrofuzz|JennyBot|JetCar|JikeSpider|JOC Web Spider|Joomla|Jorgee|JustView|Jyxobot|Kenjin Spider|Keyword Density|Kozmosbot|Lanshanbot|Larbin|LeechFTP|LeechGet|LexiBot|Lftp|LibWeb|Libwhisker|Lightspeedsystems|Likse|Linkdexbot|LinkextractorPro|LinkpadBot|LinkScan|LinksManager|LinkWalker|LinqiaMetadataDownloaderBot|LinqiaRSSBot|LinqiaScrapeBot|Lipperhey|Litemage_walker|Lmspider|LNSpiderguy|Ltx71|lwp-request|LWP\:\:Simple|lwp-trivial|Magnet|Mag-Net|magpie-crawler|Mail\.RU_Bot|Majestic12|MarkMonitor|MarkWatch|Masscan|Mass Downloader|Mata Hari|MauiBot|Meanpathbot|mediawords|MegaIndex\.ru|Metauri|MFC_Tear_Sample|Microsoft Data Access|Microsoft URL Control|MIDown tool|MIIxpc|Mister PiX|MJ12bot|Mojeek|Morfeus Fucking Scanner|Mr\.4x3|MSFrontPage|MSIECrawler|Msrabot|MS Web Services Client Protocol|muhstik-scan|Musobot|Name Intelligence|Nameprotect|Navroad|NearSite|Needle|Nessus|NetAnts|Netcraft|netEstate NE Crawler|NetLyzer|NetMechanic|NetSpider|Nettrack|Net Vampire|Netvibes|NetZIP|NextGenSearchBot|Nibbler|NICErsPRO|Niki-bot|Nikto|NimbleCrawler|Ninja|Nmap|NPbot|Nutch|oBot|Octopus|Offline Explorer|Offline Navigator|Openfind|OpenLinkProfiler|Openvas|OrangeBot|OrangeSpider|OutclicksBot|OutfoxBot|PageAnalyzer|Page Analyzer|PageGrabber|page scorer|PageScorer|Panscient|Papa Foto|Pavuk|pcBrowser|PECL\:\:HTTP|PeoplePal|PHPCrawl|Picscout|Picsearch|PictureFinder|Pimonster|Pi-Monster|Pixray|PleaseCrawl|plumanalytics|Pockey|POE-Component-Client-HTTP|Probethenet|ProPowerBot|ProWebWalker|Psbot|Pump|PxBroker|PyCurl|QueryN Metasearch|Quick-Crawler|RankActive|RankActiveLinkBot|RankFlex|RankingBot|RankingBot2|Rankivabot|RankurBot|RealDownload|Reaper|RebelMouse|Recorder|RedesScrapy|ReGet|RepoMonkey|Ripper|RocketCrawler|Rogerbot|SalesIntelligent|SBIder|ScanAlert|Scanbot|scan\.lol|Scrapy|Screaming|ScreenerBot|Searchestate|SearchmetricsBot|Semrush|SemrushBot|SEOkicks|SEOlyticsCrawler|Seomoz|SEOprofiler|seoscanners|SEOstats|sexsearcher|Seznam|SeznamBot|Shodan|Siphon|SISTRIX|Sitebeam|SiteExplorer|Siteimprove|SiteLockSpider|SiteSnagger|SiteSucker|Site Sucker|Sitevigil|Slackbot-LinkExpanding|SlySearch|SmartDownload|SMTBot|Snake|Snapbot|Snoopy|SocialRankIOBot|Sogou web spider|Sosospider|Sottopop|SpaceBison|Spammen|SpankBot|Spanner|Spbot|Spinn3r|SputnikBot|Sqlmap|Sqlworm|Sqworm|Steeler|Stripper|Sucker|Sucuri|SuperBot|SuperHTTP|Surfbot|SurveyBot|Suzuran|Swiftbot|sysscan|Szukacz|T0PHackTeam|T8Abot|tAkeOut|Teleport|TeleportPro|Telesoft|Telesphoreo|Telesphorep|The Intraformant|TheNomad|TightTwatBot|Titan|Toata|Toweyabot|Trendiction|Trendictionbot|trendiction\.com|trendiction\.de|True_Robot|Turingos|Turnitin|TurnitinBot|TwengaBot|Twice|Typhoeus|UnisterBot|URLy\.Warning|URLy Warning|Vacuum|Vagabondo|VB Project|VCI|VeriCiteCrawler|VidibleScraper|Virusdie|VoidEYE|Voil|Voltron|Wallpapers/3\.0|WallpapersHD|WASALive-Bot|WBSearchBot|Webalta|WebAuto|Web Auto|WebBandit|WebCollage|Web Collage|WebCopier|WEBDAV|WebEnhancer|Web Enhancer|WebFetch|Web Fetch|WebFuck|Web Fuck|WebGo IS|WebImageCollector|WebLeacher|WebmasterWorldForumBot|webmeup-crawler|WebPix|Web Pix|WebReaper|WebSauger|Web Sauger|Webshag|WebsiteExtractor|WebsiteQuester|Website Quester|Webster|WebStripper|WebSucker|Web Sucker|WebWhacker|WebZIP|WeSEE|Whack|Whacker|Whatweb|Who\.is Bot|Widow|WinHTTrack|WiseGuys Robot|WISENutbot|Wonderbot|Woobot|Wotbox|Wprecon|WPScan|WWW-Collector-E|WWW-Mechanize|WWW\:\:Mechanize|WWWOFFLE|x09Mozilla|x22Mozilla|Xaldon_WebSpider|Xaldon WebSpider|Xenu|xpymep1\.exe|YoudaoBot|Zade|Zauba|zauba\.io|Zermelo|Zeus|zgrab|Zitebot|ZmEu|ZumBot|ZyBorg
failregex = (?i)<HOST> -.*"(GET|POST|HEAD) (.*?)" \d+ \d+ "(.*?)" ".*(?:%(badbots)s).*"$
ignoreregex =
The results:
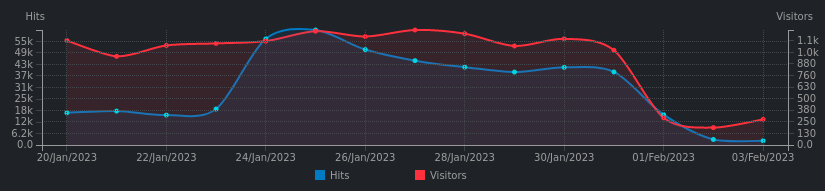
All credits go to Dale Higgs and Matthew Kressel.
The silence now is priceless.