Ctags For Markdown Notes
I keep my notes in plaintext Markdown files. Previously I used vimwiki for managing them but I felt that it was somehow bloated and its Markdown engine slightly differed from the more typical engine used in Markor (which is an Android app which I sometimes use to view and edit notes on the phone). Since I switched away from vimwiki to plain Markdown, there was one thing I missed: tags.
Generally I tag my notes and since recently I use 2 types of tags: inline tags which resemble org-mode style of tagging (:tag1:tag2:tag3:), and document-wide tags which are placed in YAML Front Matter of my Markdown files. Typical note looks like this:
---
title: Some title
tags: [foo, bar]
---
- Lorem ipsum :baz:blah:
- dolor sit amet :consecteur:
Vimwiki impements its custom way of hand-generating tags file for org-mode
style tags. Thanks to it I can jump in vim directly to the place where
selected tag is found. For example with :tjump /<tab> I can easily search
through all tags in all of my notes.
Today I managed to replicate the way of generating tags for my notes, thanks to extensibility of ctags implementation that I use: Universal Ctags.
Long story short, we have to create a file in ~/.ctags.d with the following content:
--langdef=notes
--languages=notes
--langmap=notes:.md
--kinddef-notes=t,tag,tags
--kinddef-notes=d,doctag,doctags
--_tabledef-notes=main
--_tabledef-notes=frontmatter
--_tabledef-notes=fmtags
--_mtable-regex-notes=main/---//{tenter=frontmatter}
--_mtable-regex-notes=main/:([a-zA-Z][a-zA-Z0-9]*):/\1/t/{mgroup=1}{_advanceTo=1end}
--_mtable-regex-notes=main/.//
--_mtable-regex-notes=frontmatter/^tags: *//{tenter=fmtags}
--_mtable-regex-notes=frontmatter/---//{tleave}
--_mtable-regex-notes=frontmatter/.//
--_mtable-regex-notes=fmtags/([a-zA-Z][a-zA-Z0-9]*)/\1/d/
--_mtable-regex-notes=fmtags/\]//{tleave}
--_mtable-regex-notes=fmtags/://{tleave}
--_mtable-regex-notes=fmtags/---//{tleave}{_advanceTo=0start}
--_mtable-regex-notes=fmtags/.//
This defines a new regex parser for files with .md extension. This parser is aware of its context (i.e. whether it is inside Front Matter or not) and works like this:
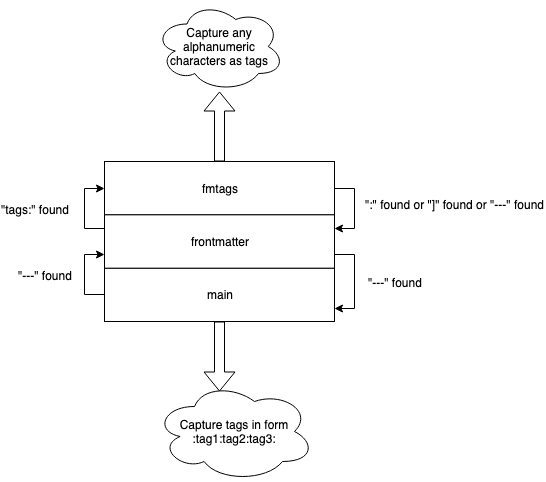
- Start in main table (context). This is generic context able to capture
org-mode style tags. Thanks to
{_advanceTo=1end}directive, a single colon between tags acts as a separator (i.e. will be the start character for the next iteration of ctags regex engine). - When we’re inside main context, look out for 3 dashes. When they’re found, push frontmatter context on top of the stack. This context itself acts as intermediate context: it will pop itself when another 3 dashes occur or it will push fmtags context when tags: text is found.
-
When in fmtags context, any alphanumeric string will be matched as a tag. This automatically handles two forms of YAML’s lists: one-line inside brackets, and multiline:
tags: [foo, bar] tags: - foo - bar -
fmtags context pops when 3 dashes or colon (some other metadata) or list closing bracket is found. 3 dashes mean end of Front Matter and thanks to
{_advanceTo=0start}after the pop they’re found again by frontmatter table, which can in turn pop again and bring us back to main context. - All tags must start with a letter (and not a number) to avoid interpreting time as a tag (e.g. 12:00:13 AM).
Ctags regex parser uses Extended Regular Expression syntax for regular
expressions as defined by POSIZ and implemented by glibc. Unfortunately it
has many limitations. For example, my tag-matching regular expression
(([a-zA-Z][a-zA-Z0-9]*)) fails to match non-ASCII characters, which is
kinda braindead in the age of Unicode. For now I changed some of my Polish
tags to their English names, but I’ll keep on searching for more elegant
solution.